The standard paradigm for improving instruction following policies involves a human manually collecting additional robot data, labelling it with language instructions, and then finetuning the policy on this data. This is an expensive endeavor, especially when improvement is desired over a multitude of environments. Can we instead leverage the policy's pre-existing capabilities to bootstrap a self-improvement process?
We present SOAR, a general-purpose robot learning system capable of autonomously improving instruction following policies. SOAR first decouples a language conditioned policy into an image-goal conditioned policy and a language conditioned image subgoal generator. With such a formulation, any autonomously collected data can be used for learning with an entirely self-supervised learning algorithm, namely hindsight-relabeled goal conditioned learning. The semantic instruction following component can then leverage the Internet-scale knowledge of semantics stored in VLMs. VLMs can be used as task proposers to bias the policy to learn to reach semantically interesting goals, and the same VLMs can automate the success detection of autonomously collected trajectories. The image-subgoal generator, also a VLM, can leverage its Internet pretraining to propose coherent, language-aligned goal images in unseen environments with unseen objects, the types of environments we most want policies to improve in.

When these components are put together, SOAR becomes an end-to-end system for autonomous improvement. SOAR can successfuly be deployed on a fleet of 5 WidowX robots to improve a language-conditioned policy on 9 different environments, collecting in the process over 25,000 autonomous trajectories in just a matter of a few weeks.
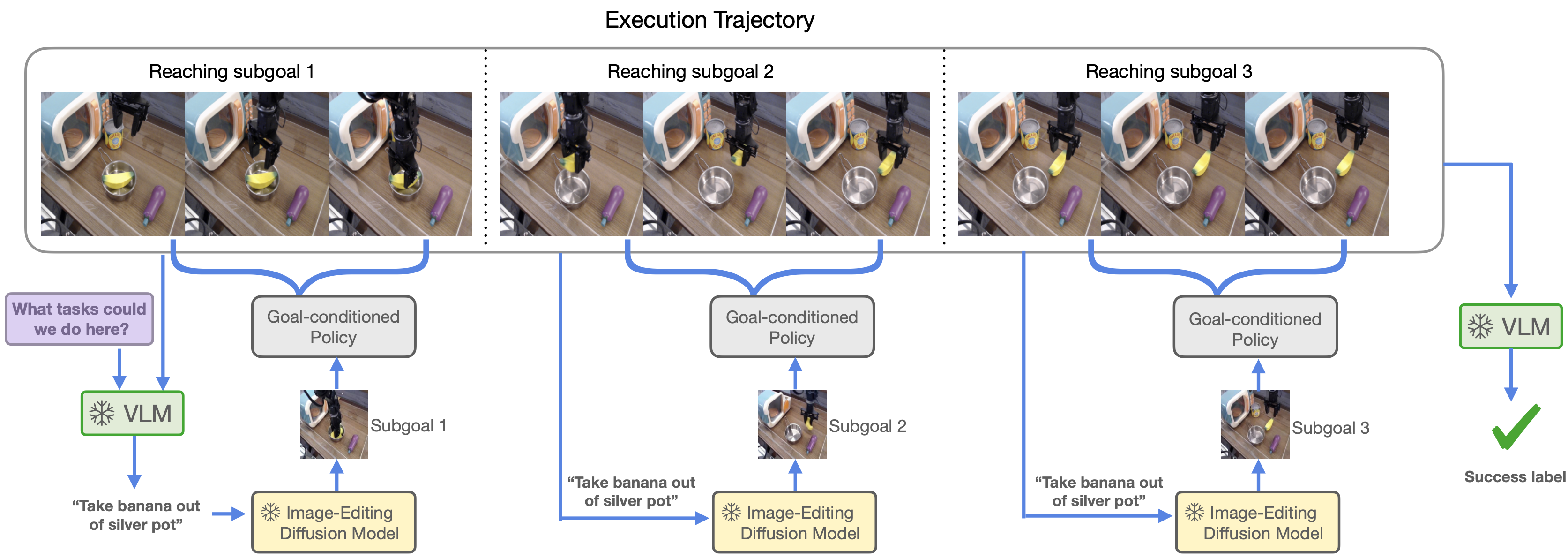
We insantiate our instruction following policy with SuSIE, a language conditioned policy decomposed as a goal conditioned policy and an InstructPix2Pix style language conditioned image editing model. Language task commands from the VLM are converted into subgoal images with the diffusion model, after which the goal conditioned policy is rolled out for a number of timesteps. Then, a new subgoal is generated with the same language instruction, and the process repeats until the end of the trajectory.
In the context of autonomous improvement, such a formulation is very useful. Semantics are separated from motor skills, allowing the former to leverage cheap Internet-data and the latter cheap autonomously collected data. Goal conditioned learning provides a more dense learning signal than language conditioned learning, and can better leverage suboptimal data. And the goal conditioned policy can be trained with purely self-supervised objectives, in contrast to a direct language conditioned policy, which would require a separate model to hindsight relabel autonomous trajectories with language.
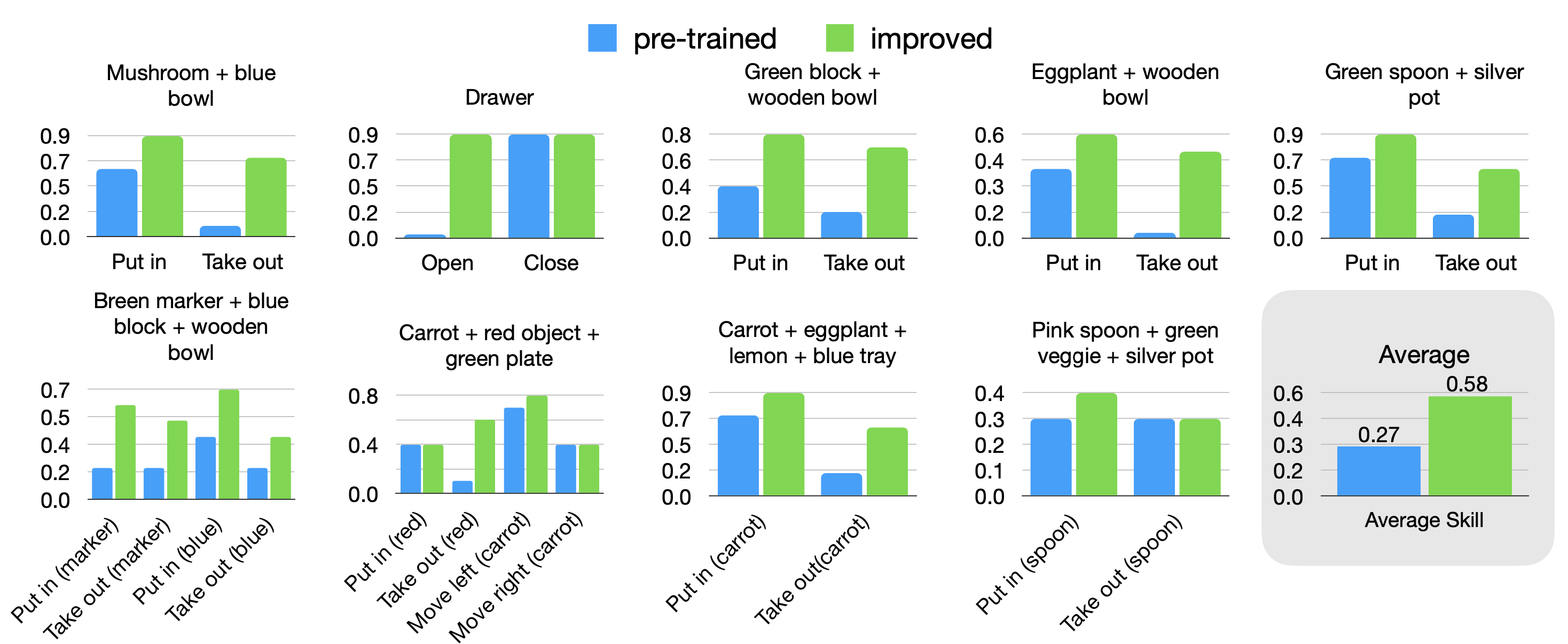
To test the improvement capabilities of SOAR, we deploy the system on nine different scenes, and on each of these scenes evaluate its ability to collect semantically useful autonomous data and subsequently learn from the data. The ability to improve is a test of both the learning procedure and the data collection procedure; if data for skills semantically relevant to the downstream tested skills has not been collected, improvement will not be evident. We find that indeed, SOAR enables improvement for multiple language skills on each of these nine scenes, with an average success rate improvement of 31%.
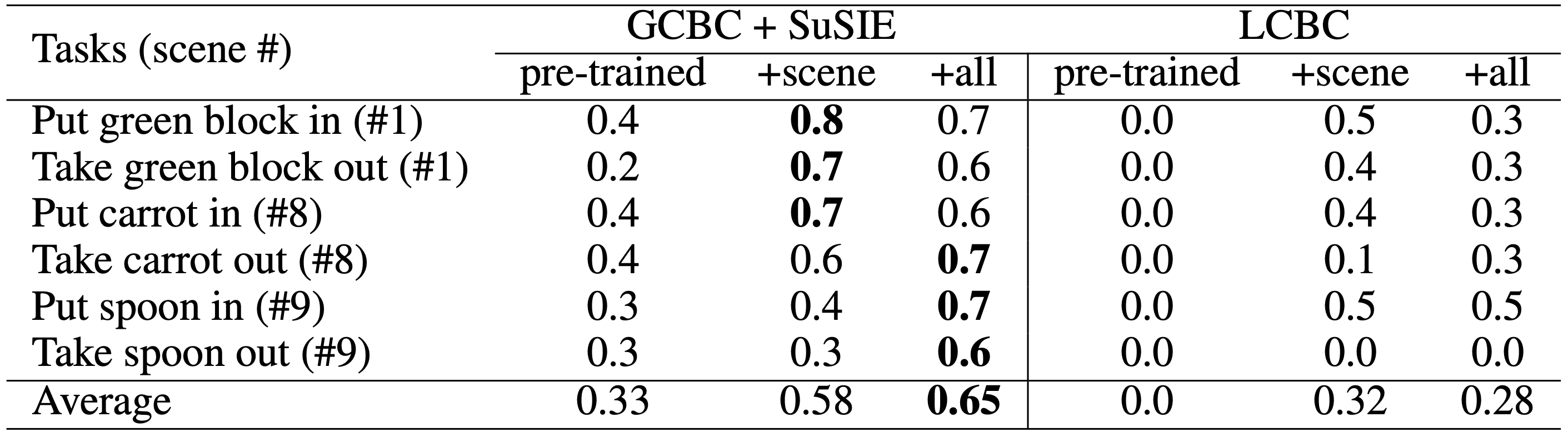
We even see positive transfer. When we train a single generalist policy on all of the collected autonomous data across the nine scenes, average success rate is 7% higher. We also ask the question whether the decomposed language conditioned policy, GCBC+SuSIE, is really needed. To answer this we train a direct language conditioned behavior cloning (LCBC) policy on the autonomous data collected by GCBC+SuSIE. While improvement is obtained by LCBC, the final performance of the decomposed policy in SOAR is considerably better. We attribute this to the increased supervision provided by a goal image than a language instruction, and the better capability of goal conditioned learning to transfer suboptimality in an autonomous trajectory into optimality for reaching the goal that was achieved.
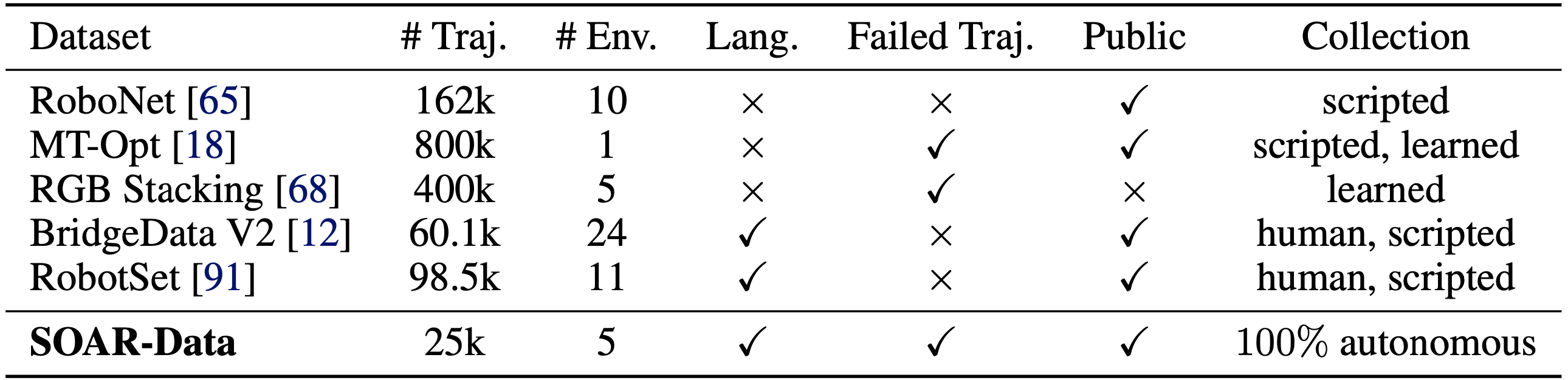
We also release as a secondary contribution the autonomous dataset collected by our deployment of SOAR. This dataset, SOAR-Data, consists of more than 25,000 trajectories (2.5M transitions) collected with over 50 different sets of objects across 5 different table top setups. Each trajectory in SOAR-Data comes with language annotations (from a VLM), 5 commanded subgoal images generated by SuSIE during one episode, and a task success label predicted by the VLM. SOAR-Data is similar in size compared to other current robotic datasets, but is collected under much smaller time frames (in a matter of weeks) with minimal human effort in the loop. As SOAR-Data consists both of failure and success trajectories, contains diverse scenes and objects, includes language instructions and subgoal images, and is collected with a publicly available low-cost robotic arm, we hope it will be a useful resource for offline reinforcement learning research.